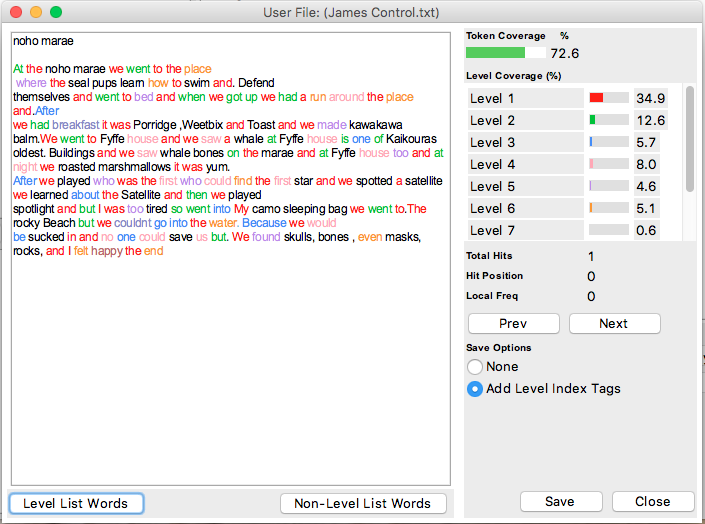
After analysing the data pushed out through Antword, this is how I have decided to summarise each child's baseline data.
File name: /Users/teacher 1/Desktop/James Control.txt
Number of types: 94
Number of tokens: 175
Type/Token ratio 53%
Statistics
Essential list
|
TOKENS
|
TOKEN%
|
CUMTOKEN%
|
TYPES
|
TYPE%
|
CUMTYPE%
| |
1
|
61
|
34.86
|
34.86
|
10
|
10.64
|
10.64
| |
2
|
22
|
12.57
|
47.43
|
12
|
12.77
|
23.41
| |
3
|
10
|
5.71
|
53.14
|
7
|
7.45
|
30.86
| |
4
|
14
|
8.00
|
61.14
|
9
|
9.57
|
40.43
| |
5
|
8
|
4.57
|
65.71
|
6
|
6.38
|
46.81
| |
6
|
9
|
5.14
|
70.85
|
8
|
8.51
|
55.32
| |
7
|
1
|
0.57
|
71.42
|
1
|
1.06
|
56.38
| |
8
|
2
|
1.14
|
72.56
|
2
|
2.13
|
58.51
| |
Not on lists
|
48
|
27.43
|
99.99
|
39
|
41.49
|
100
| |
TOTAL:
|
175
|
94
|
94
| ||||
This sample text taken on April 2016 shows that James used words from the 8 levels on the
essential lists for 73% coverage in his writing, the remaining 27% of words he has used are
not on the lists – These 48 words can be classed as high interest or topic related words.
Two were place names (Fyffe, Kaikoura) and three were kupu māori (noho, marae, kawakawa).
The aim is to see a further increase in the “off lists” usage of words that James is using to show
an increasing richness and wider use of vocabulary, beyond the essential lists. This will be reflected
in a higher type/token ratio and a higher percentage of coverage from “off list” words. In addition, new
word lists can be created from the control samples and post intervention samples and compared to show the growth
in word usage across the class.
No comments:
Post a Comment